Was ist Rendern?
| Zurück zum Inhaltsverzeichnis |
| Zurück zu: Diagramme in Blender |
| 0 - Rendern |
Im folgenden Artikel wird mit Beispielen erklärt, was wir unter Rendern verstehen , welche Faktoren beim Rendern Einfluss nehmen und wo Unterschiede zur Bilderzeugungstechniken der Photographie liegen. Anschliessend wird die Theorie mit Bildern verdeutlicht.
Rendern
Was rendern ist, lässt sich am besten mit einem Vergleich zur Photographie erläutern.
Blender zeigt uns im Fenster der 3D-Ansicht visuelle Repräsentationen
von simulierten Objekten an.
Wenn wir im Programm die Taste F12 drücken, dann wird aus der Szene ein Bild gerendert.
Rendern bedeutet, aus Daten wird ein Bild erzeugt.
Vergleich Photographie
Beim Fotoapparat ist der Prozess
der Bilderzeugung durch physikalische Faktoren festgelegt.
Das Licht welches von Objekten in die Fotokamera reflektiert wird, erzeugt in einem
automatischen Prozess ein Bild.
Je nach Einstellungen der Kamera wird mehr oder weniger Licht auf den Sensor der Kamera gelassen,
was dann Unterschiede in der Bildqualität bewirkt. In Kameras wird dazu die Blendenzeit
und die Empfindlichkeit des Sensors eingestellt.
Ein weiterer wichtiger Unterschied zwischen Photographie und Rendern ist die Abhängigkeit von äußeren Bedingungen.
Hobbyfotografen kennen die Situation, dass das Ergebnis des Prozess nicht dem entspricht,
was man sich wünschte, als man den Auslöser drückte, da sich insbesondere Lichtbedingungen schnell ändern können.
Mit solchen Problemen brauchen wir uns in der vollständig kontrollierbaren Datenwelt nicht herumschlagen.
Daten, ihre Repräsentation und der Render
Im virtuellen Raum von Programmen gibt es nur Daten und
die erzeugen erst einmal kein Bild.
Wenn ein Objekt erzeugt wird, dann kennt das Programm nur Daten.
Blender weiß, 1) es liegt ein Objekt vor.
2) Das Objekt hat an einer bestimmten Stelle einen Mittelpunkt.
3) Das Objekt besitzt eventuell einige Punkte als geometrische Daten.
4) Die Punkte sind eventuell durch Kanten verbunden.
5) Das Objekt hat (k)ein Material.
Der Rest liegt nicht als elementare Daten vor, sondern wird als Repräsentation aus den Daten erstellt. Wie diese Daten interpretiert werden, dass lässt sich verändern. Wir können in der 3-D Ansicht z. B. den Anzeigemodus verändern und aus unserem scheinbar dreidimensionalen Objekt wird auf Knopfdruck eine Strichzeichnung, ohne erkennbare Flächen.
Auf den ersten Blick könnten wir sagen: Das Ansehen der 3D-Szene ist wie das Ansehen einer Szene durch den Sucher - ohne den Auslöser zu drücken. Aber das ist falsch, da wir durch den Sucher die Realität, bzw. die mit Filtern modifizierte Realität sehen. In der 3-D Ansicht sehen wir hingegen eine Interpretation von Daten. Wir können vielleicht sagen dass diese Daten der Realität entsprechen, aber Daten kann man nicht sehen. Ohne aufwändige Bestimmung von Interpretationsvorgaben sehen wir nichts. Eine solche Interpretationsvorgabe im Solidmode von Blender ist, dass eine Fläche mit einer bestimmten Farbe zu zeichnen ist, wenn mindestens drei Punkte miteinander verbunden sind.
Zum Teil lässt sich die 3D-Szene nicht so rendern, wie wir sie in der 3-D Ansicht sehen - z. B. in der Ansicht des Drahtgittermodus. Hier liegen keine entsprechenden Interpretationsvorgaben vor, die Kanten rendern können. Um Render von Kanten zu erhalten brauchen wir einen sog. Modifier, vom Typ Wireframe, der aus den Kanten echte Geometrie interpretiert. Den Modifier können wir dann hinsichtlich der Kantendicke weiter einstellen. Und so geht es mit allen erdenklichen Effekten die wir aus der Realität kennen. Licht und Schatteneffekte, Brennweite, Reflexionen, Transparenz und viele mehr, müssen manuell eingestellt werden. Einerseits ermöglicht diese Unterbestimmtheit des 3-D Raums mehr Spielraum für Kreativität, da wir nicht an die Gesetze der Realität gebunden sind, andererseits ist damit auch mehr Arbeit verbunden, um realistische Bilder zu simulieren.
In den folgenden Bildern sehen wir die Unterschiede zwischen den Bildern der 3D-Szene und dem gerenderten Bild. Sowohl hinsichtlich visueller Eigenschaften, als auch strukturell vom Bildinhalt.

Visuelle Eigenschaften 1
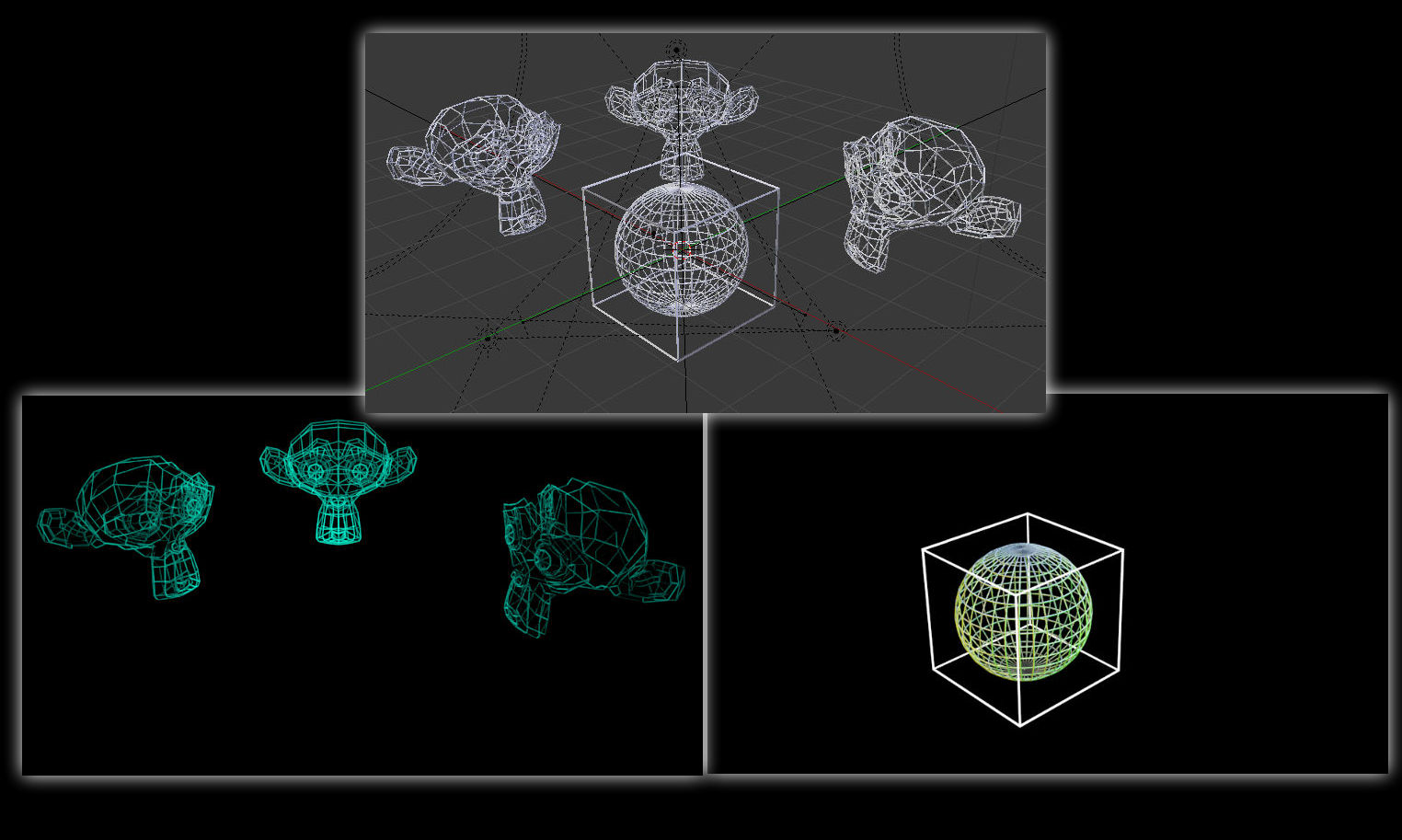
Hier sehen wir die 3D-Szene in Blender im Solid Shadingmodus.
Schatten werden nicht berechnet, Oberflächenfarben fehlen.
Der Solidmode dient dazu möglichst leistungsarm zu Arbeiten,
da aufwändige Simulationen den Arbeitsprozess durch Stocken verlangsamen können.

Visuelle Eigenschaften 2
Der Wireframemode zeigt keine Flächen an, sondern nur Kanten.
Dieses Bild lässt sich überhaupt nicht rendern,
weil Blender keine Interpretationsrichtlinien kennt, um den Gitternetzmodus in ein Bild umzuwandeln.
Gitternetzobjekte lassen sich in Blender nur rendern, indem Objekten sog. Modifier zugewiesen werden,
welche die Interpretation der Struktur für den Renderprozess verändern.

Visuelle Eigenschaften 3
So sieht das gerenderte Bild der Szene der vorherigen Bilder aus.
Hier wurde der Hintergrund nicht mitgerendert.
Ansonsten sähe man - den Standardeinstellungen folgend - ein langweiliges grau.
Ausserdem erkennen wir Schatten und bei einem einzigen Objekt auch Oberflächenfarben.
Das rechte Objekt wirkt abgerundet, weil ein sog. Modifier als eine zusätzliche Interpretationsrichtlinie,
hier erst auf den Renderprozess angewendet wurde.
Bildinhalte
Neben dem Aspekt der visuellen Details sieht man im folgenden Bild,
dass auch die Bildstruktur nicht mit der Szene übereinstimmen muss.
Inhalte in einer Szene lassen sich aus dem Renderprozess entfernen, ohne die Szene zu verändern.
Beim Fotografieren mit Fotoapparat und Smartphone sind wir Fotobombern hingegen schutzlos ausgeliefert ;)
Wir können zwar Objekte wegretuschieren, doch anders als in der 3D-Szene fehlt dann der Hintergrund.
Dateninterpretation und Rendern
Der Rendervorgang ist, wenn wir ihn mit Tastendruck auf F12 auslösen, zwar gefühlt wie das Auslösen einer
Fotokamera, jedoch im Mechanismus komplett unterschiedlich.
Die Fotokamera erstellt aus Licht das auf den Sensor trifft ein Bild.
Blender hingegen erstellt beim Rendern aus A) den Geometriedaten der Szene B) Oberflächendaten/Bildern (Texturen)
C) Interpretationsrichtlinien, wie Schatten/Licht zu berechnen sind und D) Zusatzeffekten wie Reflektionen,
ein Bild. Wie oben gesehen, muss es nicht ein einziges gerendertes Bild sein.
Aus einer Szene lassen sich über das Ebenensystem (Renderlayer) mehrere unterschiedliche Bilder
aus einer Szene rendern. Dies tut man, um Spezialeffekte in der Bildnachbearbeitung nur auf Teile des
Bildes anzuwenden.
Der Renderprozess dauert bei Objekten mit vielen tausend Flächen oder komplizierten Licht/Schatten-Berechnungen (Shading) lange. Bilder aus spezieleffektlastigen Animationsfilmen benötigen selbst am Gamer-PC mehrere Stunden bis Tage an Renderzeit - bis ein einzelnes Bild vollständig gerendert ist.
Zurück zum Hauptartikel: Diagramme in Blender
klicken Sie auf das Bild:
